AlphaDDA: strategies for adjusting the playing strength of a fully
Por um escritor misterioso
Last updated 31 março 2025
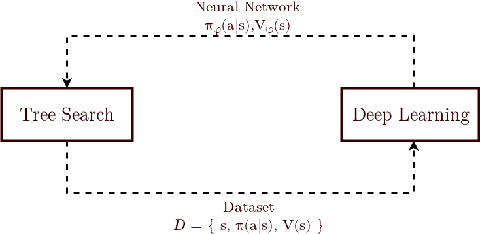
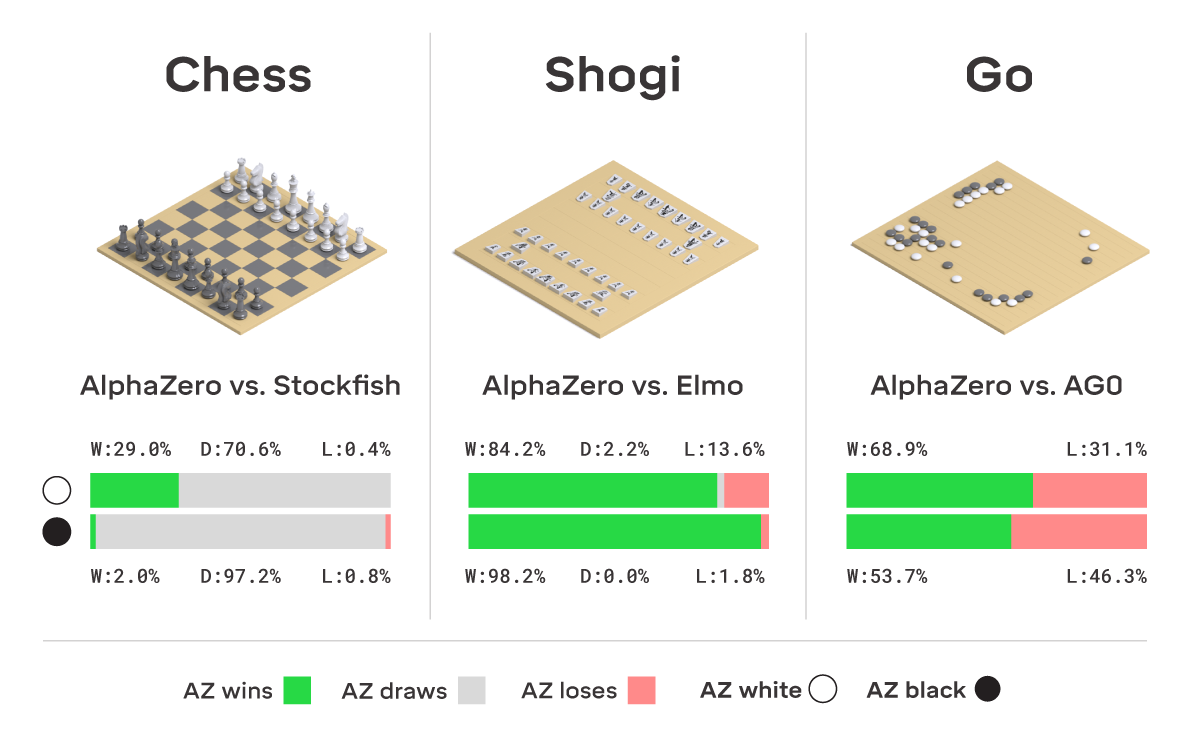
Artificial intelligence (AI) has achieved superhuman performance in board games such as Go, chess, and Othello (Reversi). In other words, the AI system surpasses the level of a strong human expert player in such games. In this context, it is difficult for a human player to enjoy playing the games with the AI. To keep human players entertained and immersed in a game, the AI is required to dynamically balance its skill with that of the human player. To address this issue, we propose AlphaDDA, an AlphaZero-based AI with dynamic difficulty adjustment (DDA). AlphaDDA consists of a deep neural network (DNN) and a Monte Carlo tree search, as in AlphaZero. AlphaDDA learns and plays a game the same way as AlphaZero, but can change its skills. AlphaDDA estimates the value of the game state from only the board state using the DNN. AlphaDDA changes a parameter dominantly controlling its skills according to the estimated value. Consequently, AlphaDDA adjusts its skills according to a game state. AlphaDDA can adjust its skill using only the state of a game without any prior knowledge regarding an opponent. In this study, AlphaDDA plays Connect4, Othello, and 6x6 Othello with other AI agents. Other AI agents are AlphaZero, Monte Carlo tree search, the minimax algorithm, and a random player. This study shows that AlphaDDA can balance its skill with that of the other AI agents, except for a random player. AlphaDDA can weaken itself according to the estimated value. However, AlphaDDA beats the random player because AlphaDDA is stronger than a random player even if AlphaDDA weakens itself to the limit. The DDA ability of AlphaDDA is based on an accurate estimation of the value from the state of a game. We believe that the AlphaDDA approach for DDA can be used for any game AI system if the DNN can accurately estimate the value of the game state and we know a parameter controlling the skills of the AI system.

arxiv-sanity

arxiv-sanity
PDF] A0C: Alpha Zero in Continuous Action Space

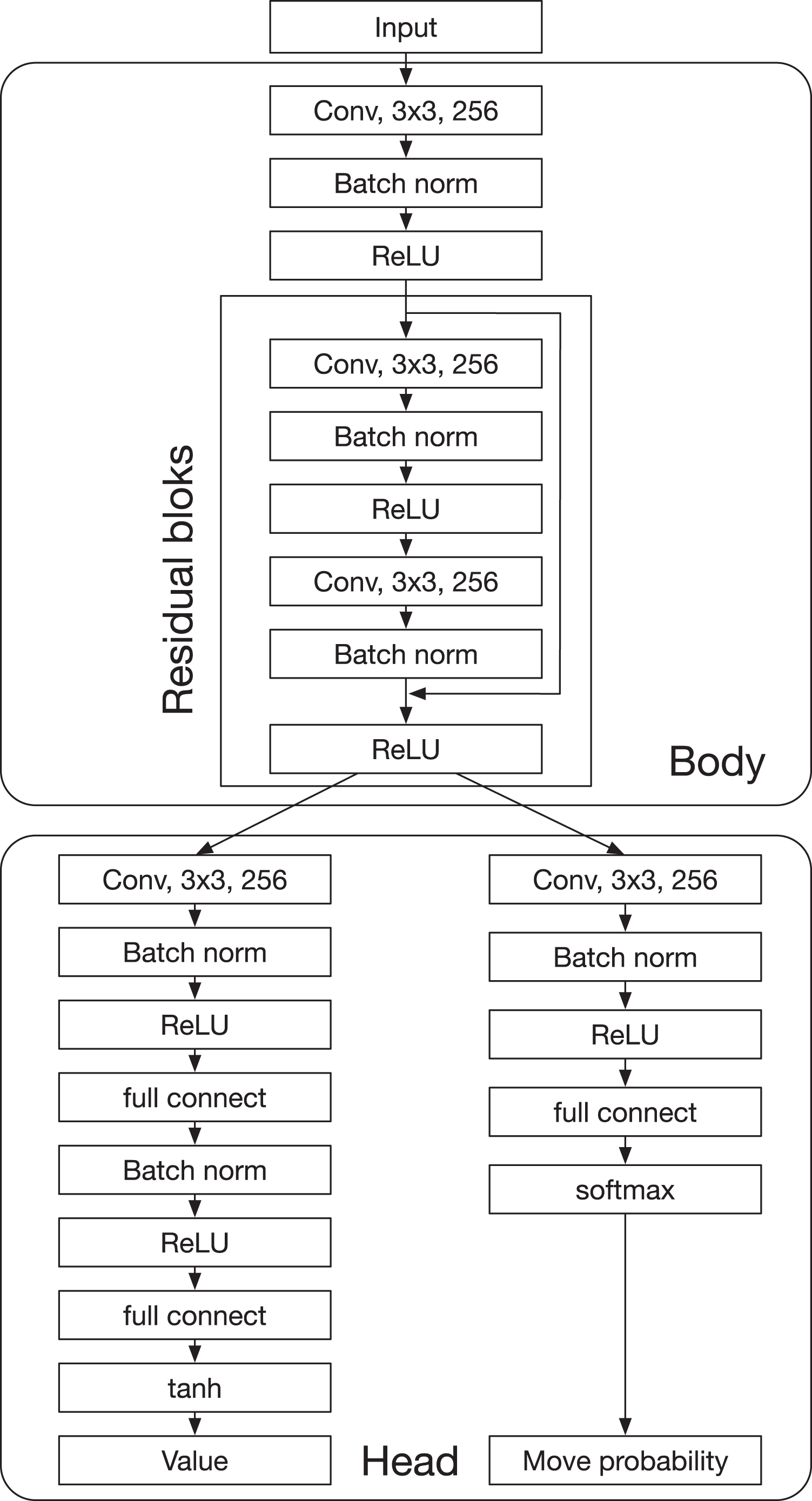
Figure A1 Deep neural network of AlphaDDA. Full-size DOI

研究概要

CliftonStrengths Adaptability - StrengthsFinder Talent #3 Of 34

Schematic diagram of the Dynamic Difficulty Adjustment system.

User learning curve Download Scientific Diagram

Games won and lost during the one hundred 30 minute training games. The
Recomendado para você
-
 AlphaZero — US Pycon December 2019 documentation31 março 2025
AlphaZero — US Pycon December 2019 documentation31 março 2025 -
Alphazero Chess Download PNG - Google-Keresés31 março 2025
-
 🔵 AlphaZero Plays Connect 431 março 2025
🔵 AlphaZero Plays Connect 431 março 2025 -
 Alpha Zero and Monte Carlo Tree Search31 março 2025
Alpha Zero and Monte Carlo Tree Search31 março 2025 -
 Evaluation Beyond Task Performance: Analyzing Concepts in31 março 2025
Evaluation Beyond Task Performance: Analyzing Concepts in31 março 2025 -
alpha-zero · GitHub Topics · GitHub31 março 2025
-
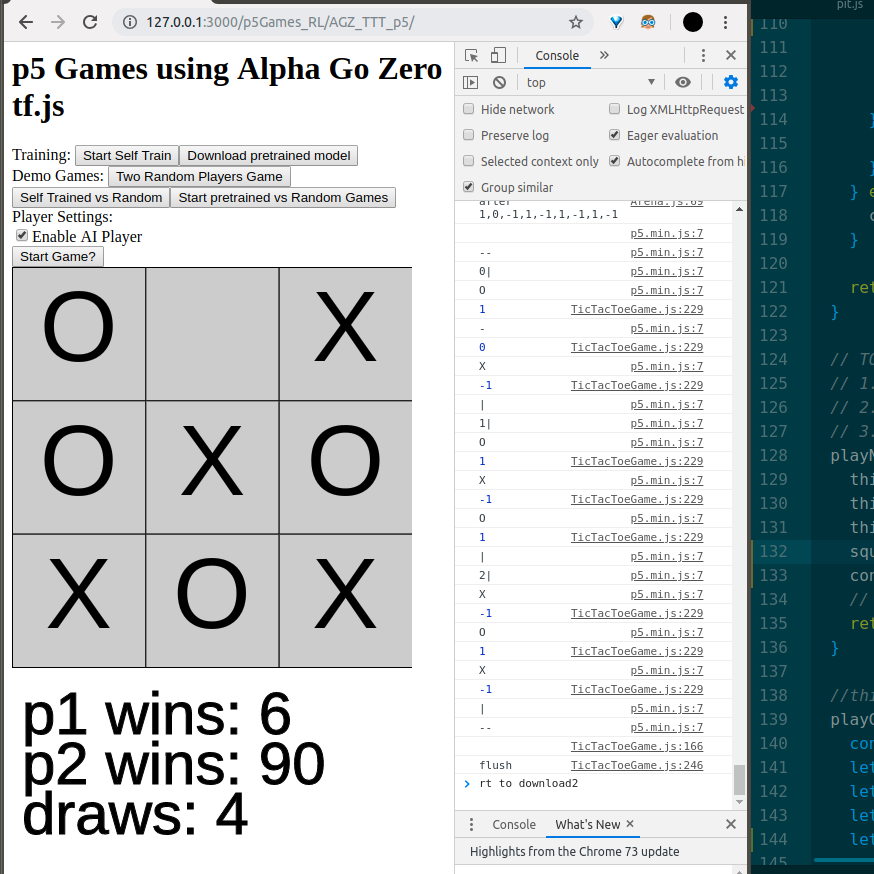 Alpha Zero General playing Tic Tac Toe in p5 using tf.js — J31 março 2025
Alpha Zero General playing Tic Tac Toe in p5 using tf.js — J31 março 2025 -
AlphaZero like implementation for Oware Abapa game - AlphaZero31 março 2025
-
 PDF) Tackling Morpion Solitaire with AlphaZero-likeRanked Reward31 março 2025
PDF) Tackling Morpion Solitaire with AlphaZero-likeRanked Reward31 março 2025 -
 AlphaZero - Chessprogramming wiki31 março 2025
AlphaZero - Chessprogramming wiki31 março 2025
você pode gostar
-
 Good Mini Games on X: Tomb Runner (running & jumping online game) dynamical online game #games #running #online / X31 março 2025
Good Mini Games on X: Tomb Runner (running & jumping online game) dynamical online game #games #running #online / X31 março 2025 -
BEST Fruit for EVERY Race Awakening V4!!! #bloxfruits #bloxfruit31 março 2025
-
 How the Queen enchanted and influenced Commonwealth leaders, Royal, News31 março 2025
How the Queen enchanted and influenced Commonwealth leaders, Royal, News31 março 2025 -
 80s & 90s Dragon Ball Art Dragon ball art, Dragon ball, Dragon ball z31 março 2025
80s & 90s Dragon Ball Art Dragon ball art, Dragon ball, Dragon ball z31 março 2025 -
 The greatest and lowest extent of soviet Union : r/MapPorn31 março 2025
The greatest and lowest extent of soviet Union : r/MapPorn31 março 2025 -
Snapchat is getting its own multiplayer version of Subway Surfers31 março 2025
-
![Is Norman Alive? 6 Theories [The Promised Neverland]](https://i.ytimg.com/vi/hsvkcoHrs2s/maxresdefault.jpg) Is Norman Alive? 6 Theories [The Promised Neverland]31 março 2025
Is Norman Alive? 6 Theories [The Promised Neverland]31 março 2025 -
 The Best Sites To Download Retro Games For Free31 março 2025
The Best Sites To Download Retro Games For Free31 março 2025 -
 Flee the Facility Roblox Game Review ✓31 março 2025
Flee the Facility Roblox Game Review ✓31 março 2025 -
 Ilya ILYUKHIN31 março 2025
Ilya ILYUKHIN31 março 2025

