XQuAD Dataset Papers With Code
Por um escritor misterioso
Last updated 28 março 2025

XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating cross-lingual question answering performance. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 (Rajpurkar et al., 2016) together with their professional translations into ten languages: Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. Consequently, the dataset is entirely parallel across 11 languages.
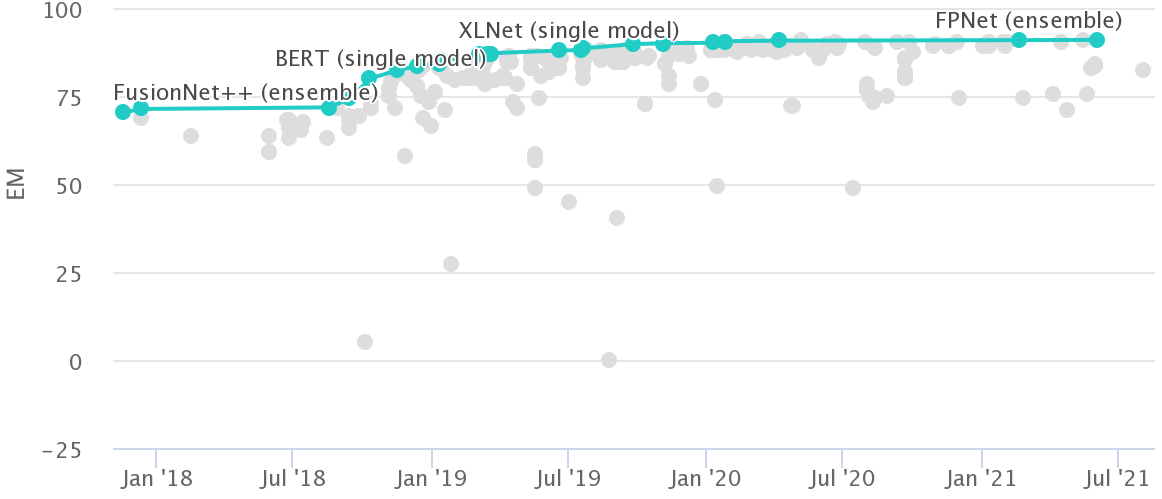
Challenges and Opportunities in NLP Benchmarking

SQuAD Dataset Papers With Code
GitHub - chiahsuan156/Spoken-SQuAD: A spoken question answering
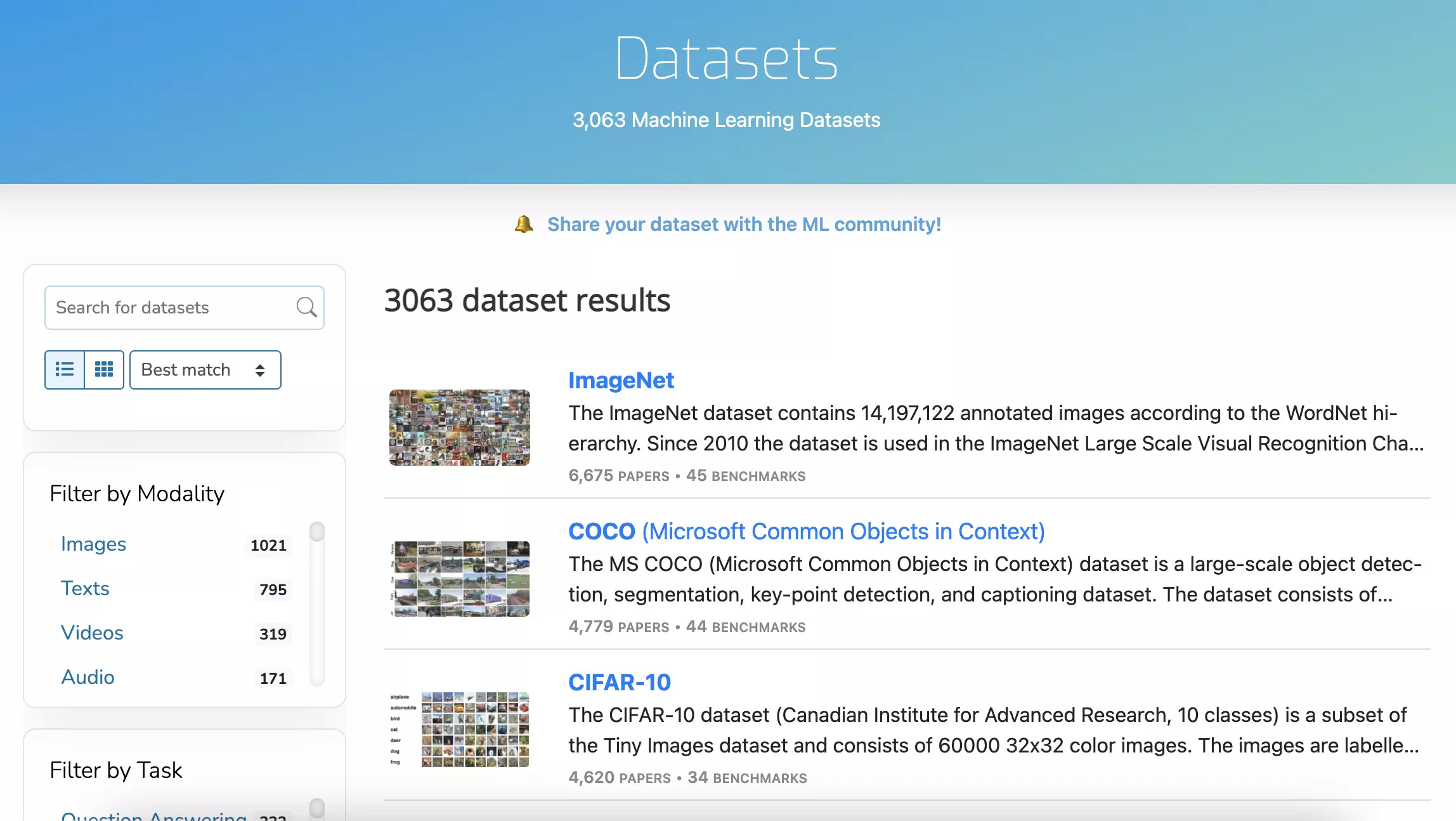
Machine Learning Datasets

SQuAD model sentence relation and deep semantics error

NukeBERT: A Pre-trained language model for Low Resource Nuclear

UAVVaste Dataset Papers With Code
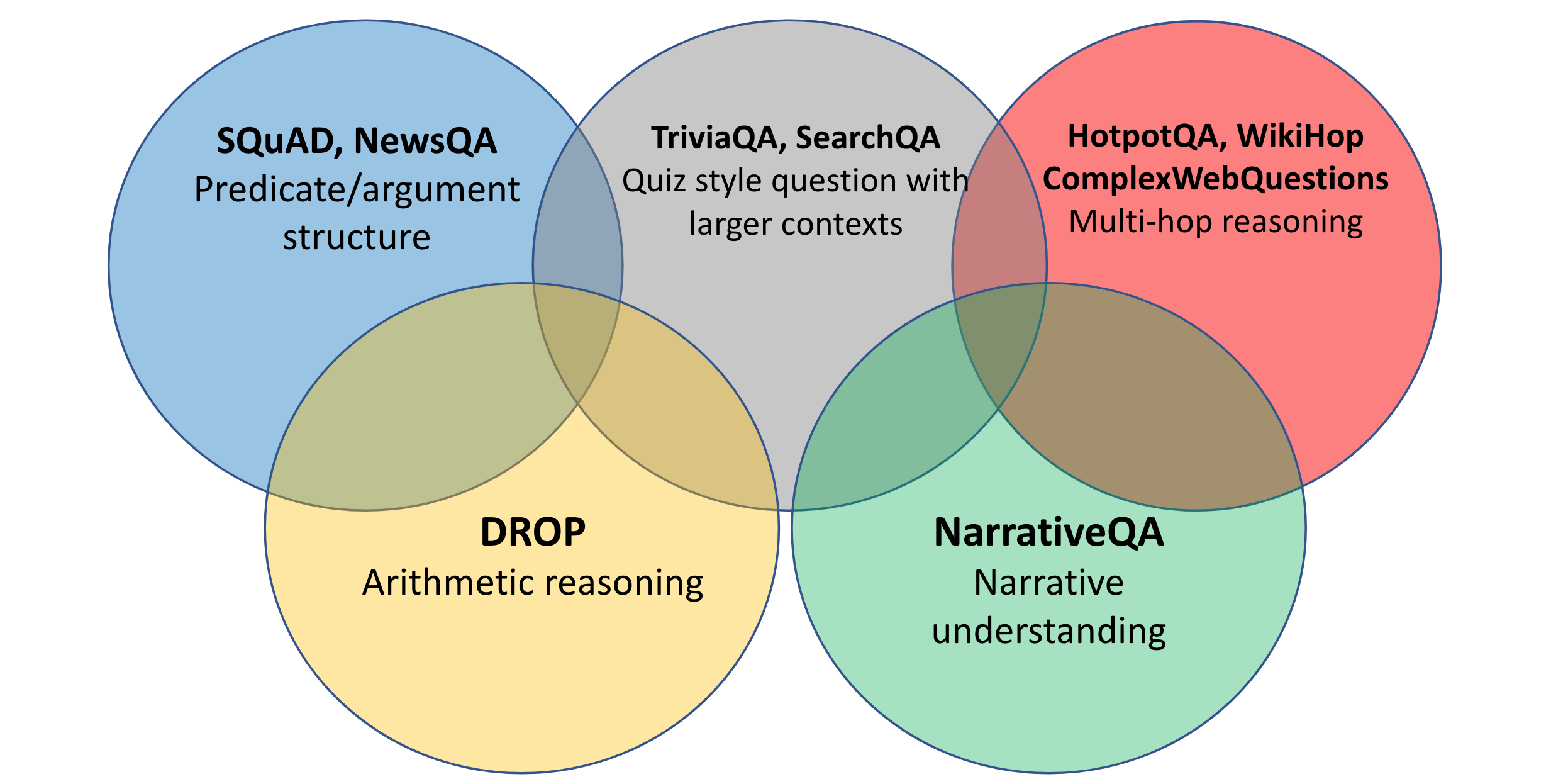
Multi-domain Multilingual Question Answering

CovidQA Dataset Papers With Code

How SIGNAL IDUNA operationalizes machine learning projects on AWS
Recomendado para você
-
 Internal Combustion Engines 2013-2014 BE Mechanical Engineering Semester 6 (TE Third Year) Old question paper with PDF download28 março 2025
Internal Combustion Engines 2013-2014 BE Mechanical Engineering Semester 6 (TE Third Year) Old question paper with PDF download28 março 2025 -
 Gas Turbine Interview Questions and Answers - Power Plant28 março 2025
Gas Turbine Interview Questions and Answers - Power Plant28 março 2025 -
300+ TOP I.C. ENGINES Objective Questions and Answers PDF MCQs, PDF, Internal Combustion Engine28 março 2025
-
 Pin on Engineering28 março 2025
Pin on Engineering28 março 2025 -
 300 Important Compressors, Gas Turbines And Jet Engines MCQ Question and Answer28 março 2025
300 Important Compressors, Gas Turbines And Jet Engines MCQ Question and Answer28 março 2025 -
 ASIS-PCI Dumps Guide For a Effective Exam Preparation, by Rebecca28 março 2025
ASIS-PCI Dumps Guide For a Effective Exam Preparation, by Rebecca28 março 2025 -
 Dk & Eng - Engine - Page 1 - Witherbys28 março 2025
Dk & Eng - Engine - Page 1 - Witherbys28 março 2025 -
 Azusa Pacific University Network28 março 2025
Azusa Pacific University Network28 março 2025 -
 Valid Salesforce Networks Web Services Education-Cloud-Consultant Dumps pdf 2023 by Olivia James - Issuu28 março 2025
Valid Salesforce Networks Web Services Education-Cloud-Consultant Dumps pdf 2023 by Olivia James - Issuu28 março 2025 -
 Internal Combustion Engines: Expository Reading by Creative Curricula28 março 2025
Internal Combustion Engines: Expository Reading by Creative Curricula28 março 2025
você pode gostar
-
![♟️ Create an Online Chess Game - Placement Grid - 1/5 [Unity tutorial 2021][C#]](https://i.ytimg.com/vi/FtGy7J8XD90/maxresdefault.jpg) ♟️ Create an Online Chess Game - Placement Grid - 1/5 [Unity tutorial 2021][C#]28 março 2025
♟️ Create an Online Chess Game - Placement Grid - 1/5 [Unity tutorial 2021][C#]28 março 2025 -
Creed - My Sacrifice by COPYDRUM28 março 2025
-
 QUEM É A ESPOSA DE BOBAN MARJANOVIC? TUDO SOBRE SEU CASAMENTO E FILHOS - ENTRETENIMENTO28 março 2025
QUEM É A ESPOSA DE BOBAN MARJANOVIC? TUDO SOBRE SEU CASAMENTO E FILHOS - ENTRETENIMENTO28 março 2025 -
 Tattletail mobile three fan games for fun number 1 where is mama?/Tattletail is harder then Original28 março 2025
Tattletail mobile three fan games for fun number 1 where is mama?/Tattletail is harder then Original28 março 2025 -
 Certified Pre-Owned 2023 Rolls-Royce Cullinan Black Badge SUV in Mt. Laurel #PU21668128 março 2025
Certified Pre-Owned 2023 Rolls-Royce Cullinan Black Badge SUV in Mt. Laurel #PU21668128 março 2025 -
Level 12 #roblox #apeirophobia #fun #backrooms28 março 2025
-
 Animes parecidos com Horimiya - DICAS DE ANIMES28 março 2025
Animes parecidos com Horimiya - DICAS DE ANIMES28 março 2025 -
 What's your opinion on soul of gold? : r/SaintSeiya28 março 2025
What's your opinion on soul of gold? : r/SaintSeiya28 março 2025 -
 Tabuada Para Imprimir: Sem Resultados. Contas de Multiplicação do 1 ao 9. … Tabuada de multiplicação, Fichas de exercícios de matemática, Atividades de matemática28 março 2025
Tabuada Para Imprimir: Sem Resultados. Contas de Multiplicação do 1 ao 9. … Tabuada de multiplicação, Fichas de exercícios de matemática, Atividades de matemática28 março 2025 -
![Read I Can Copy Talents Manga English [New Chapters] Online Free - MangaClash](https://cdn1.mangaclash.com/temp/manga_6108c2f93f0cb/e66327dad1e3c3707a650d6b25822281/1.jpg) Read I Can Copy Talents Manga English [New Chapters] Online Free - MangaClash28 março 2025
Read I Can Copy Talents Manga English [New Chapters] Online Free - MangaClash28 março 2025
