PDF) Incorporating representation learning and multihead attention
Por um escritor misterioso
Last updated 31 março 2025

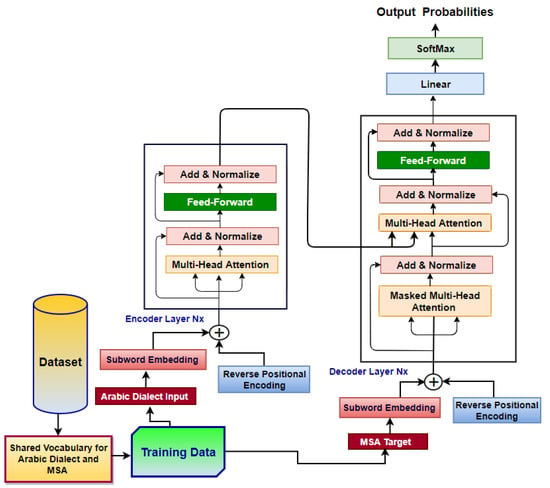
Mathematics, Free Full-Text

Multi-head enhanced self-attention network for novelty detection - ScienceDirect
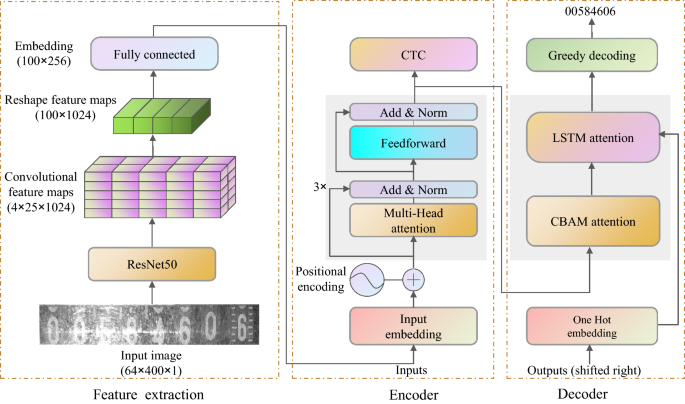
Multiple attention-based encoder–decoder networks for gas meter character recognition
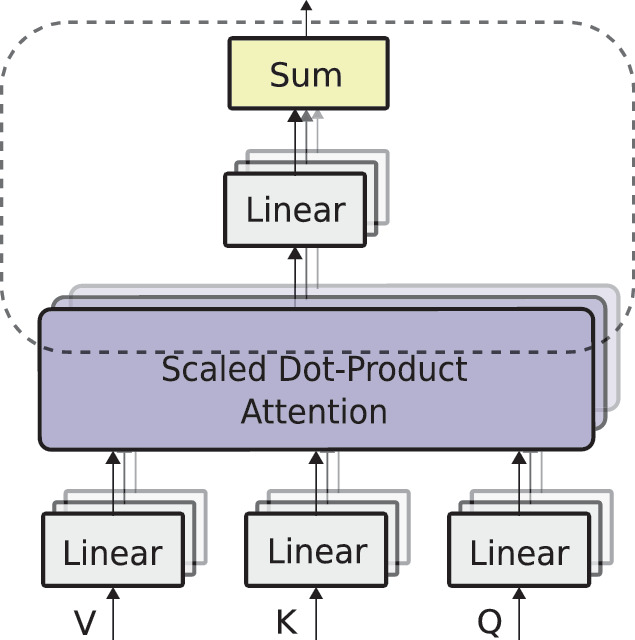
Software and Hardware Fusion Multi-Head Attention

Sensors, Free Full-Text
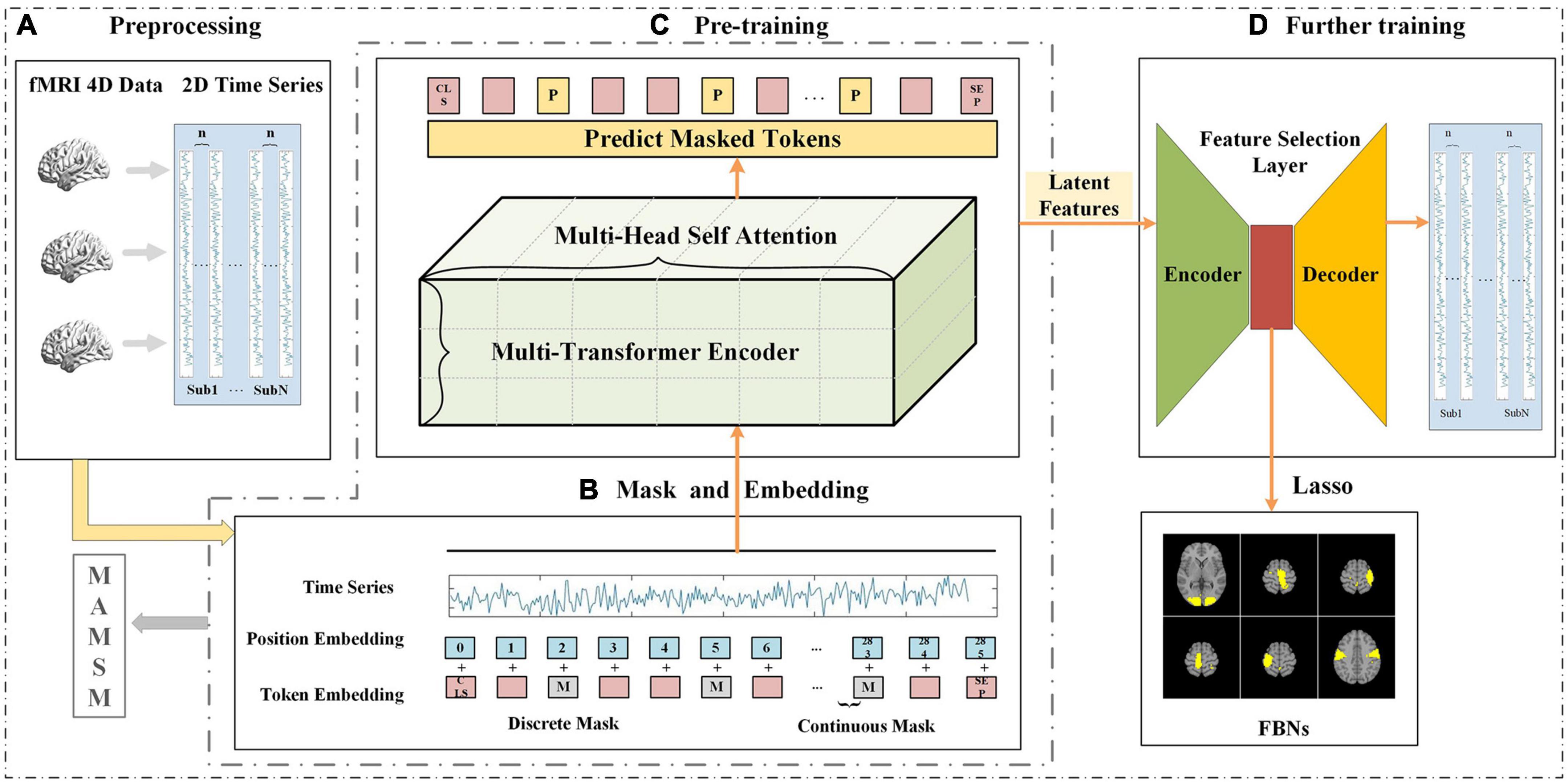
Frontiers Multi-head attention-based masked sequence model for mapping functional brain networks
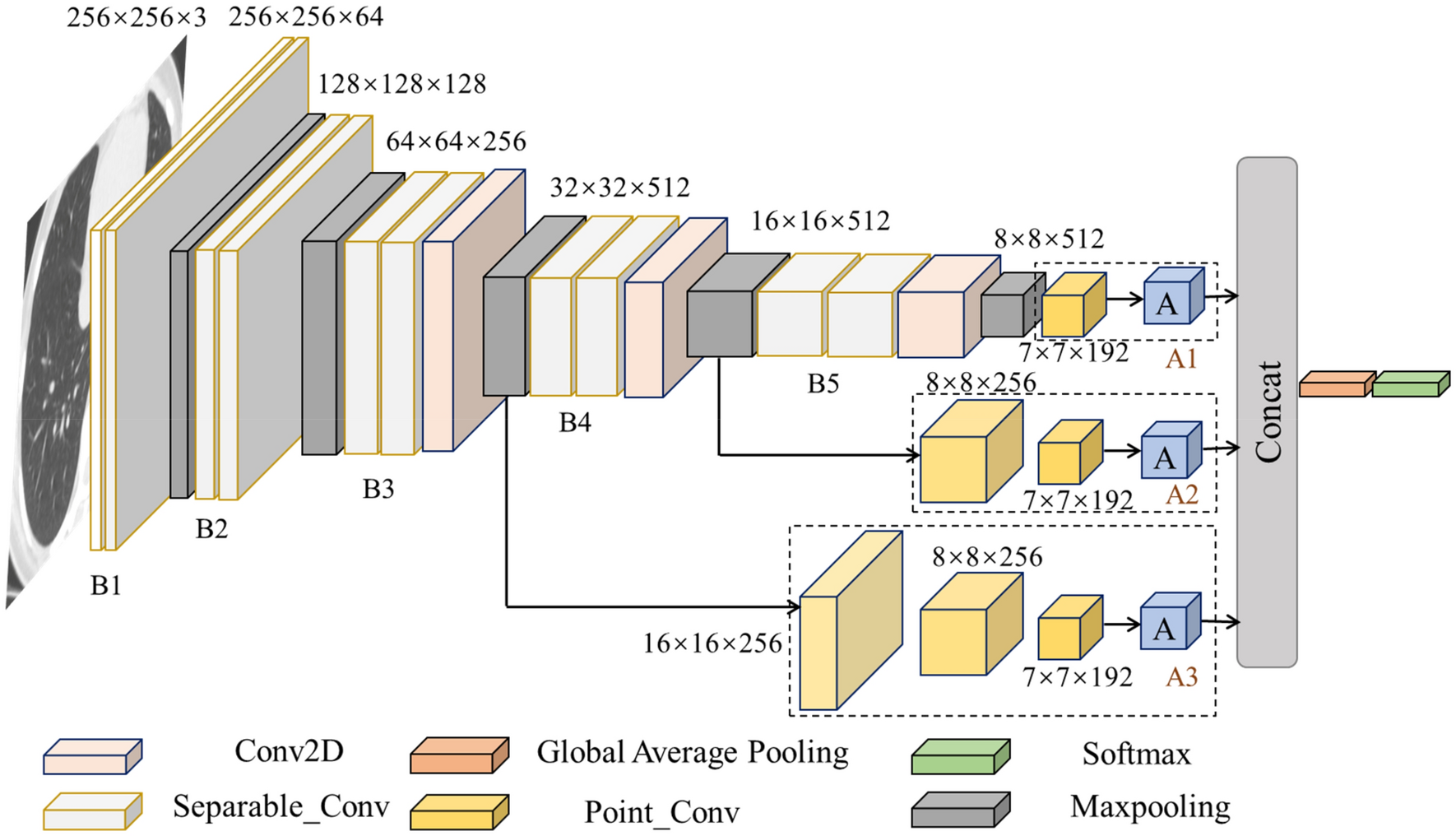
A multi-scale gated multi-head attention depthwise separable CNN model for recognizing COVID-19

Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders – arXiv Vanity
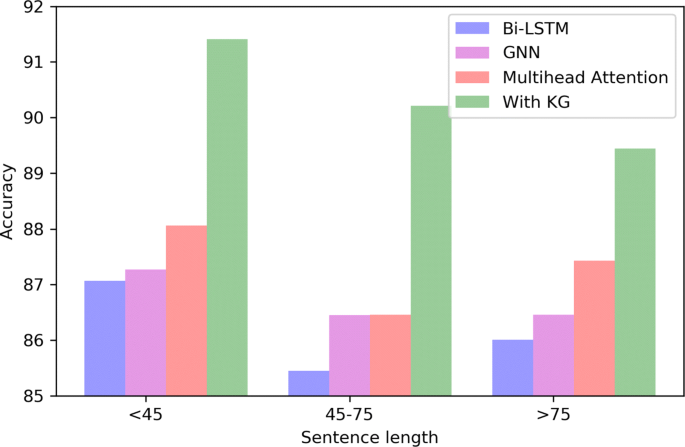
Incorporating representation learning and multihead attention to improve biomedical cross-sentence n-ary relation extraction, BMC Bioinformatics
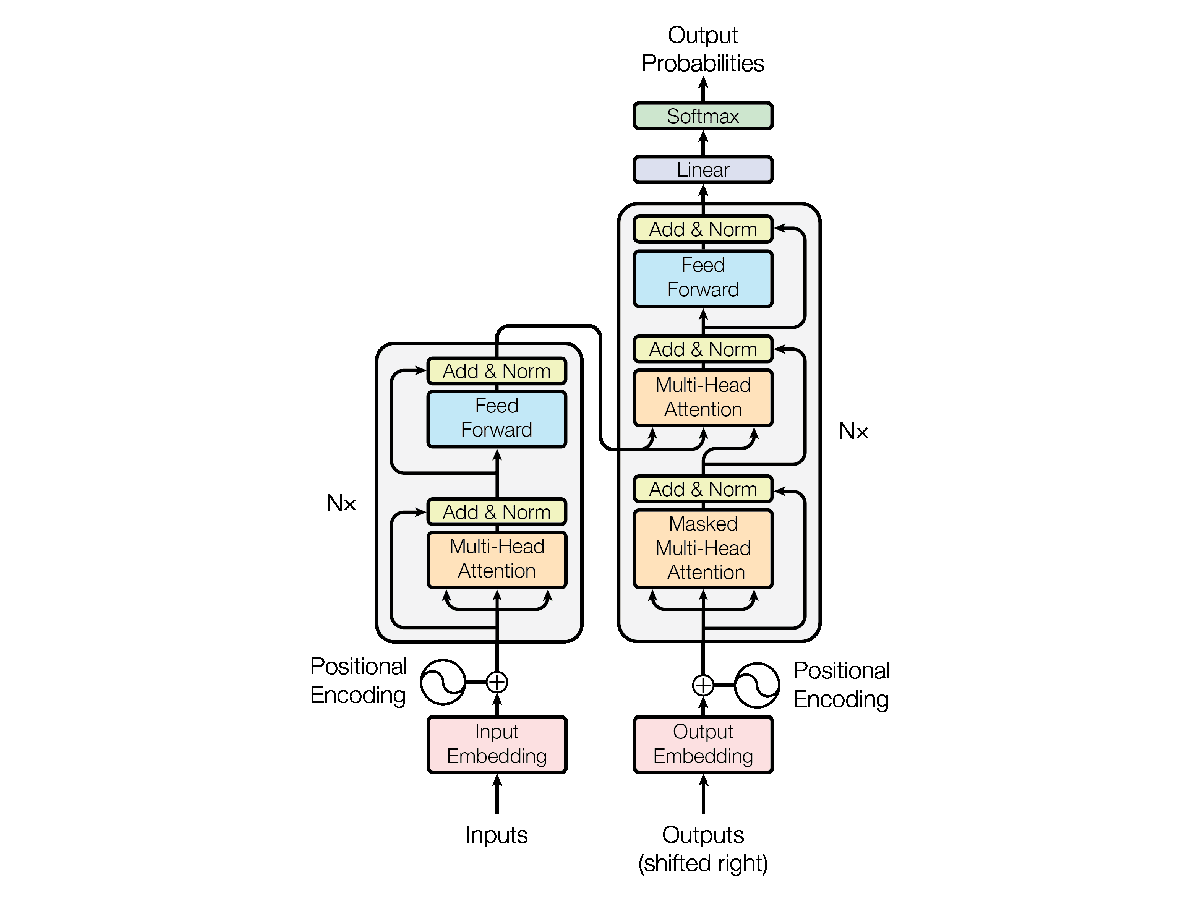
Understanding the Transformer Model: A Breakdown of “Attention is All You Need”, by Srikari Rallabandi, MLearning.ai
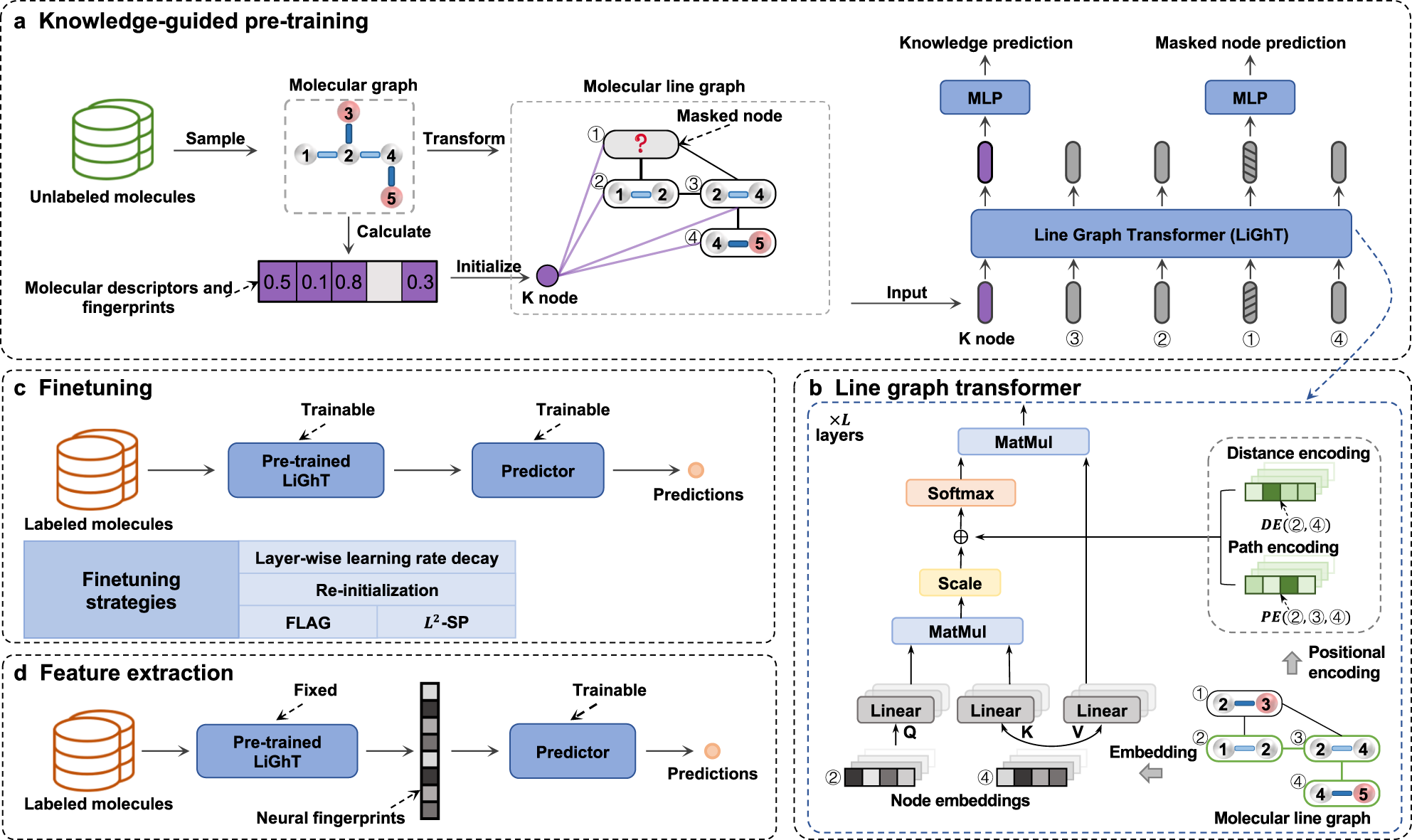
A knowledge-guided pre-training framework for improving molecular representation learning
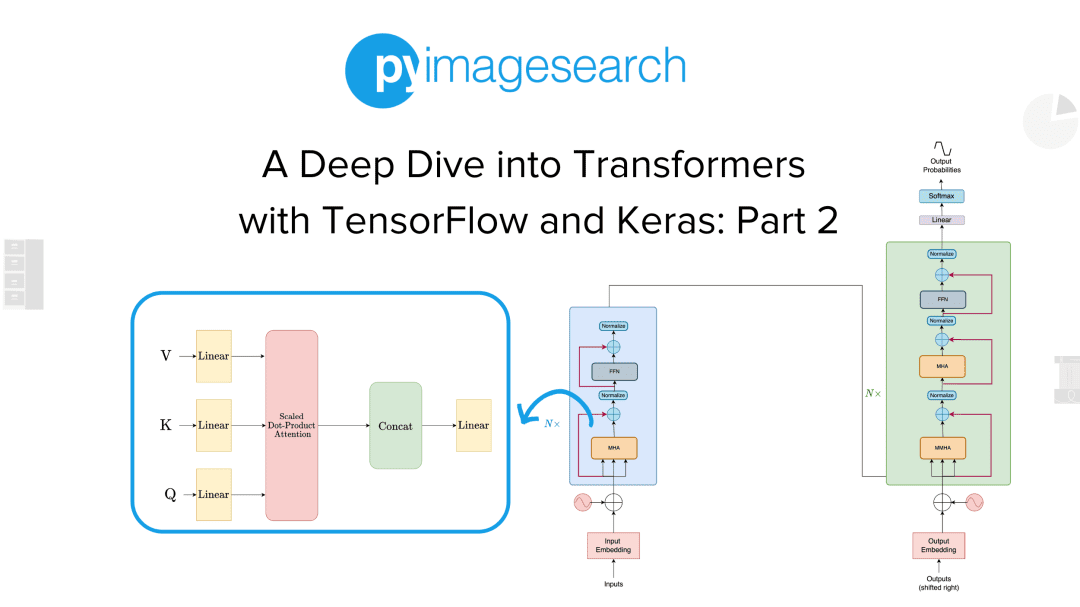
A Deep Dive into Transformers with TensorFlow and Keras: Part 2 - PyImageSearch
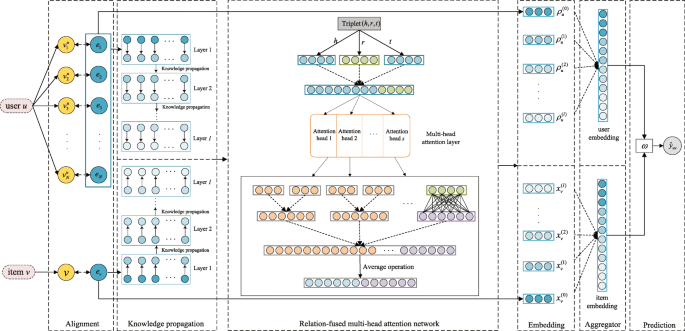
RFAN: Relation-fused multi-head attention network for knowledge graph enhanced recommendation
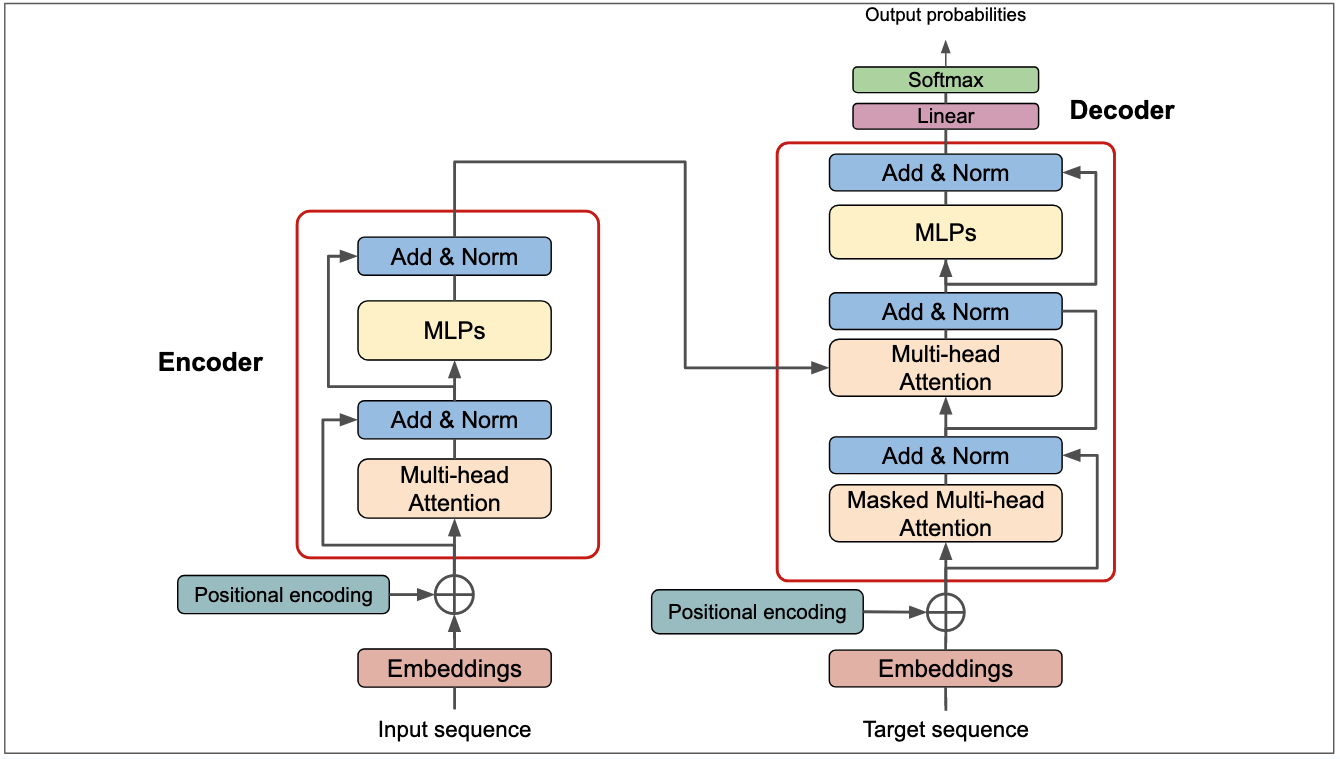
AI Research Blog - The Transformer Blueprint: A Holistic Guide to the Transformer Neural Network Architecture
Recomendado para você
-
 Use Crosscheck In A Sentence31 março 2025
Use Crosscheck In A Sentence31 março 2025 -
 CoinGecko on X: #Crypto Word Of The Day: Arbitrage Used in a31 março 2025
CoinGecko on X: #Crypto Word Of The Day: Arbitrage Used in a31 março 2025 -
 Using the cross as a personal adornment has been en voguesince the31 março 2025
Using the cross as a personal adornment has been en voguesince the31 março 2025 -
 Fangyu Liu on X: Want to bootstrap your sentence similarity model31 março 2025
Fangyu Liu on X: Want to bootstrap your sentence similarity model31 março 2025 -
English Made Easy - ✏️WORD OF THE DAY✏️ Today's word is31 março 2025
-
 Decodable Readers Multisyllables Open Syllables Books and Lesson31 março 2025
Decodable Readers Multisyllables Open Syllables Books and Lesson31 março 2025 -
 July 2021 – The GDELT Project31 março 2025
July 2021 – The GDELT Project31 março 2025 -
 Direction: Read the sentence. Put a check (/) mark on the space31 março 2025
Direction: Read the sentence. Put a check (/) mark on the space31 março 2025 -
 10 Tautology Examples (2023)31 março 2025
10 Tautology Examples (2023)31 março 2025 -
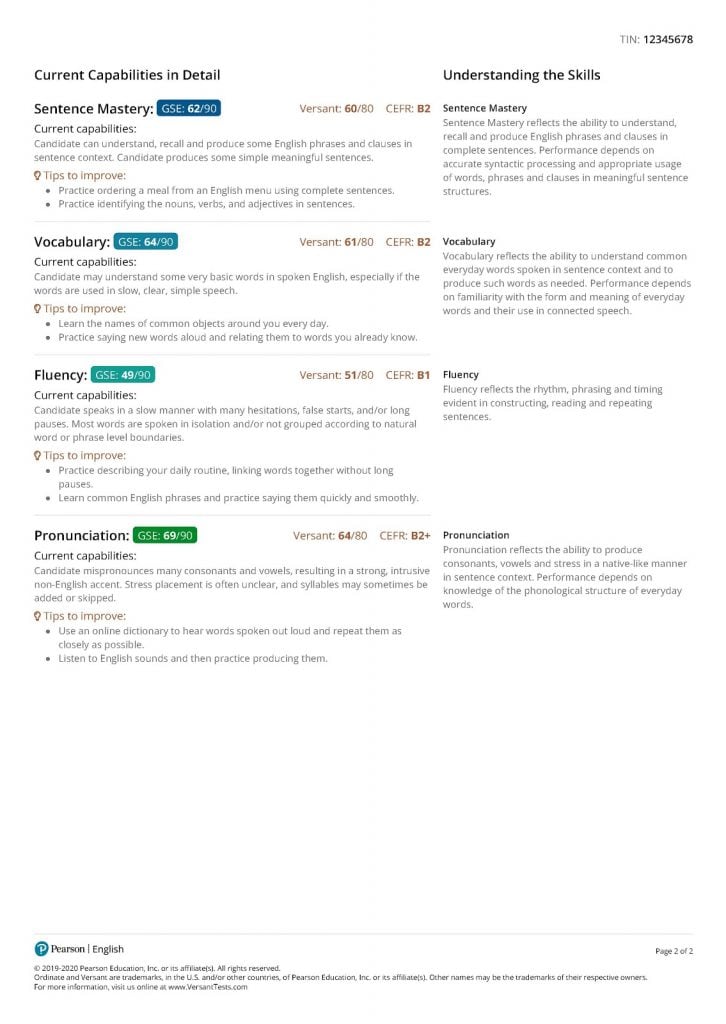 Pearson's ScoreKeeper 3: the new and improved test management31 março 2025
Pearson's ScoreKeeper 3: the new and improved test management31 março 2025

você pode gostar
-
 Bobcats Make History With First Win On Road - SWVA SUN31 março 2025
Bobcats Make History With First Win On Road - SWVA SUN31 março 2025 -
 Dominando as Aberturas de Xadrez - Volume 131 março 2025
Dominando as Aberturas de Xadrez - Volume 131 março 2025 -
 10 animes clássicos para assistir na Netflix31 março 2025
10 animes clássicos para assistir na Netflix31 março 2025 -
The Love Plug31 março 2025
-
 F1 22 - Miami Sizzle Trailer31 março 2025
F1 22 - Miami Sizzle Trailer31 março 2025 -
 Pokédex Paldea: Todos os Pokémon de Pokémon Scarlet e Violet e31 março 2025
Pokédex Paldea: Todos os Pokémon de Pokémon Scarlet e Violet e31 março 2025 -
 Stranger Things: Netflix divulga trailer da 4ª temporada; assista31 março 2025
Stranger Things: Netflix divulga trailer da 4ª temporada; assista31 março 2025 -
 Terry Riley - Wikipedia31 março 2025
Terry Riley - Wikipedia31 março 2025 -
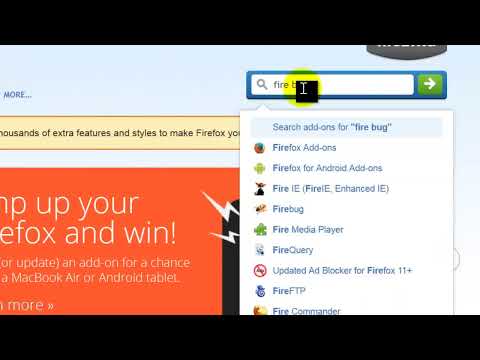 How to Install Plugins in Mozilla Firefox31 março 2025
How to Install Plugins in Mozilla Firefox31 março 2025 -
 sciphotos on X: Empresário de Enner Valencia começou a seguir o Inter no Instagram / X31 março 2025
sciphotos on X: Empresário de Enner Valencia começou a seguir o Inter no Instagram / X31 março 2025
