Policy or Value ? Loss Function and Playing Strength in AlphaZero
Por um escritor misterioso
Last updated 28 março 2025
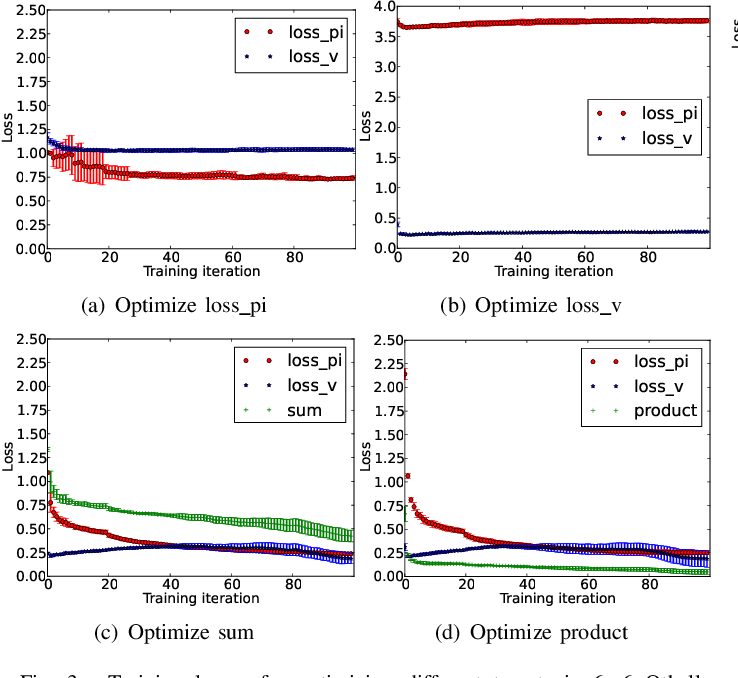
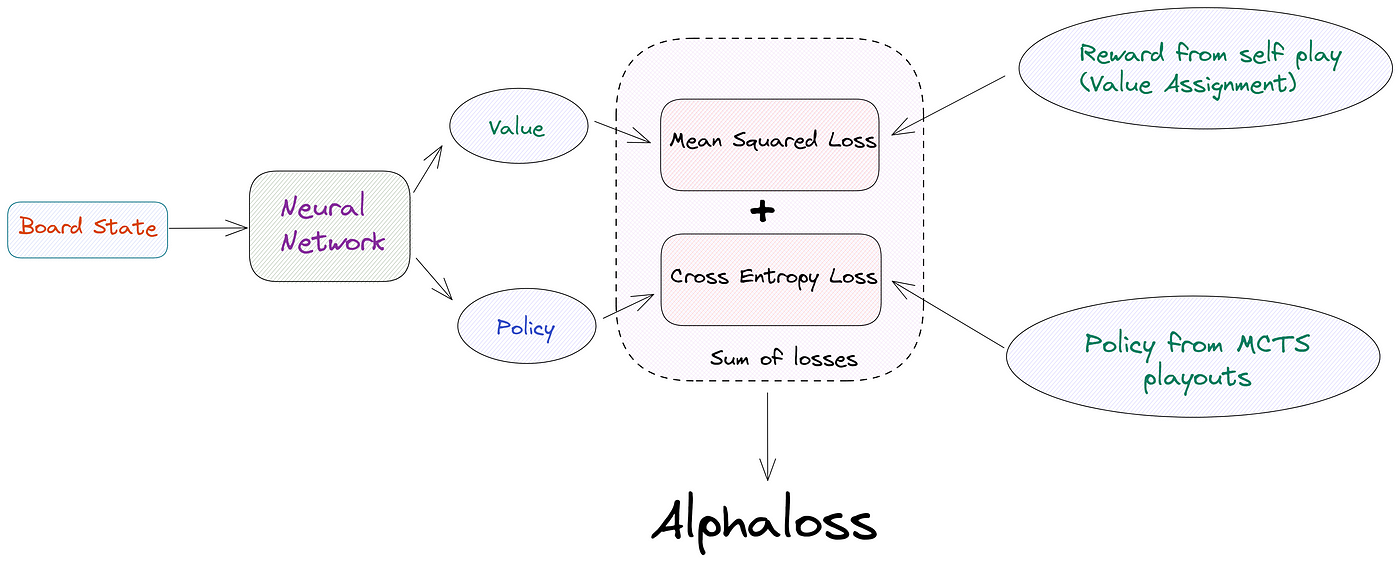
Results indicate that, at least for relatively simple games such as 6x6 Othello and Connect Four, optimizing the sum, as AlphaZero does, performs consistently worse than other objectives, in particular by optimizing only the value loss. Recently, AlphaZero has achieved outstanding performance in playing Go, Chess, and Shogi. Players in AlphaZero consist of a combination of Monte Carlo Tree Search and a Deep Q-network, that is trained using self-play. The unified Deep Q-network has a policy-head and a value-head. In AlphaZero, during training, the optimization minimizes the sum of the policy loss and the value loss. However, it is not clear if and under which circumstances other formulations of the objective function are better. Therefore, in this paper, we perform experiments with combinations of these two optimization targets. Self-play is a computationally intensive method. By using small games, we are able to perform multiple test cases. We use a light-weight open source reimplementation of AlphaZero on two different games. We investigate optimizing the two targets independently, and also try different combinations (sum and product). Our results indicate that, at least for relatively simple games such as 6x6 Othello and Connect Four, optimizing the sum, as AlphaZero does, performs consistently worse than other objectives, in particular by optimizing only the value loss. Moreover, we find that care must be taken in computing the playing strength. Tournament Elo ratings differ from training Elo ratings—training Elo ratings, though cheap to compute and frequently reported, can be misleading and may lead to bias. It is currently not clear how these results transfer to more complex games and if there is a phase transition between our setting and the AlphaZero application to Go where the sum is seemingly the better choice.

AlphaGo Zero – How and Why it Works – Tim Wheeler
Electronics, Free Full-Text

Monte-Carlo Graph Search for AlphaZero – arXiv Vanity

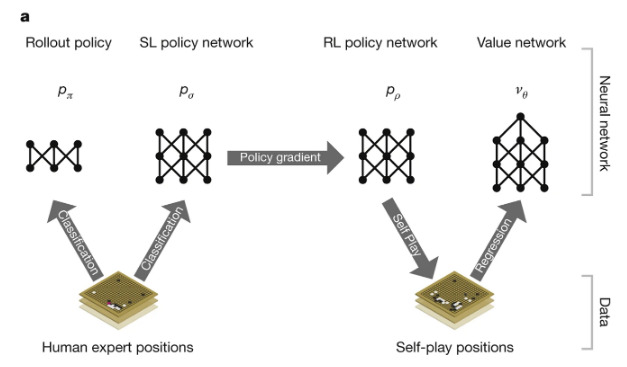
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
AlphaGo/AlphaGoZero/AlphaZero/MuZero: Mastering games using progressively fewer priors
AlphaZero from scratch in PyTorch for the game of Chain Reaction — Part 3, by Bentou

Frontiers AlphaZe∗∗: AlphaZero-like baselines for imperfect information games are surprisingly strong

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

Acquisition of chess knowledge in AlphaZero
AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]
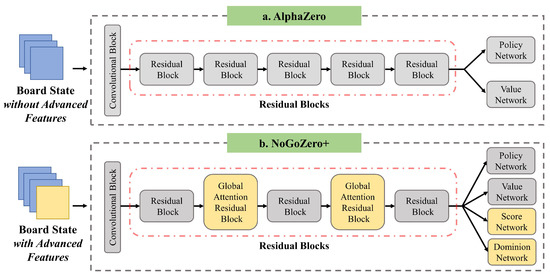
Electronics, Free Full-Text
Recomendado para você
-
 New AlphaZero Paper Explores Chess Variants28 março 2025
New AlphaZero Paper Explores Chess Variants28 março 2025 -
 AlphaZero, Vladimir Kramnik and reinventing chess28 março 2025
AlphaZero, Vladimir Kramnik and reinventing chess28 março 2025 -
 AlphaZero Vs StockFish – A Literature Review.pptx28 março 2025
AlphaZero Vs StockFish – A Literature Review.pptx28 março 2025 -
 Mastering the game of Go without human knowledge28 março 2025
Mastering the game of Go without human knowledge28 março 2025 -
 AlphaZero: A General Reinforcement Learning Algorithm that Masters Chess, Shogi and Go through Self-Play28 março 2025
AlphaZero: A General Reinforcement Learning Algorithm that Masters Chess, Shogi and Go through Self-Play28 março 2025 -
 Google's self-learning AI AlphaZero masters chess in 4 hours28 março 2025
Google's self-learning AI AlphaZero masters chess in 4 hours28 março 2025 -
 STREET FIGHTER ALPHA ZERO KEN ANIME PRODUCTION CEL 428 março 2025
STREET FIGHTER ALPHA ZERO KEN ANIME PRODUCTION CEL 428 março 2025 -
 Free Course: DeepMind's AlphaGo Zero and AlphaZero, RL paper explained from Aleksa Gordić - The AI Epiphany28 março 2025
Free Course: DeepMind's AlphaGo Zero and AlphaZero, RL paper explained from Aleksa Gordić - The AI Epiphany28 março 2025 -
Does AlphaGo Zero threaten data science field since Zero doesn't need big data training and analysis? - Quora28 março 2025
-
 Move over AlphaGo: AlphaZero taught itself to play three different games28 março 2025
Move over AlphaGo: AlphaZero taught itself to play three different games28 março 2025
você pode gostar
-
 Personagens Com os Mesmos Dubladores! on X: Menções honrosas: - Kyouko Honda (Fruits Basket 2019) - Gammamon (Digimon Ghost Game) - Ultear Milkovich (Fairy Tail) - Kaiser de Emperana Beelzebub IV (Beelzebub)28 março 2025
Personagens Com os Mesmos Dubladores! on X: Menções honrosas: - Kyouko Honda (Fruits Basket 2019) - Gammamon (Digimon Ghost Game) - Ultear Milkovich (Fairy Tail) - Kaiser de Emperana Beelzebub IV (Beelzebub)28 março 2025 -
:strip_icc()/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2022/E/2/WI1ZcpQY6VmN1iJwACIg/netflix-jobs-3-.jpg) Netflix Jobs: como se candidatar a vagas para trabalhar na Netflix28 março 2025
Netflix Jobs: como se candidatar a vagas para trabalhar na Netflix28 março 2025 -
 Full Exception Anime Soundtrack Now Available On Music Streaming Platforms28 março 2025
Full Exception Anime Soundtrack Now Available On Music Streaming Platforms28 março 2025 -
 Mesa e cadeiras varanda Black Friday Casas Bahia28 março 2025
Mesa e cadeiras varanda Black Friday Casas Bahia28 março 2025 -
 TEIS8 The eminence in shadow garden CID KAGENOU Sama copy / copying MARY quotes anime manga light novel characters season 2 ep 1 saying kage no jitsuryokusha ni naritakute cosplay October 2023 - Cid - Pin28 março 2025
TEIS8 The eminence in shadow garden CID KAGENOU Sama copy / copying MARY quotes anime manga light novel characters season 2 ep 1 saying kage no jitsuryokusha ni naritakute cosplay October 2023 - Cid - Pin28 março 2025 -
i am best arras.io play im better than corrupt x and corrupt y28 março 2025
-
 Tails.EXE by poppingperi on DeviantArt28 março 2025
Tails.EXE by poppingperi on DeviantArt28 março 2025 -
 In 'Twisted Metal,' Stephanie Beatriz and Anthony Mackie Rethink Killer Clowns - The New York Times28 março 2025
In 'Twisted Metal,' Stephanie Beatriz and Anthony Mackie Rethink Killer Clowns - The New York Times28 março 2025 -
 The Cuphead Show but only Ms Chalice28 março 2025
The Cuphead Show but only Ms Chalice28 março 2025 -
 Ludwig Chess Boxing Merch28 março 2025
Ludwig Chess Boxing Merch28 março 2025